| bin | ||
| demo | ||
| docs | ||
| .gitignore | ||
| .prettierignore | ||
| .prettierrc.json | ||
| dalai | ||
| index.js | ||
| package.json | ||
| yarn.lock | ||
Dalai
Dead simple way to run LLaMA on your computer.
JUST RUN THIS:
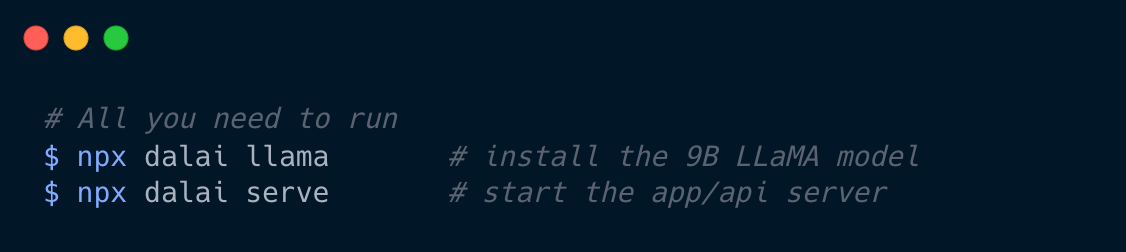
TO GET:
- Powered by llama.cpp and llama-dl CDN
- Hackable web app included
- Ships with JavaScript API
- Ships with Socket.io API
Quickstart
Install the 7B model (default) and start a web UI:
npx dalai llama
npx dalai serve
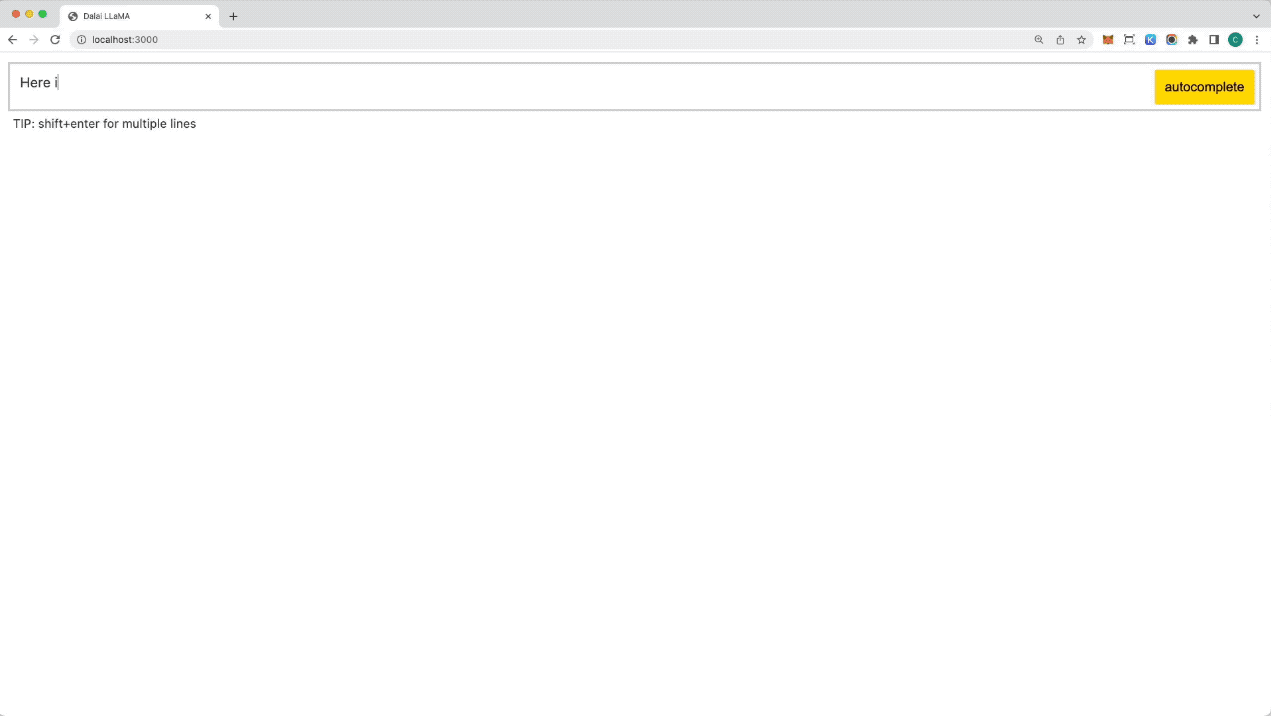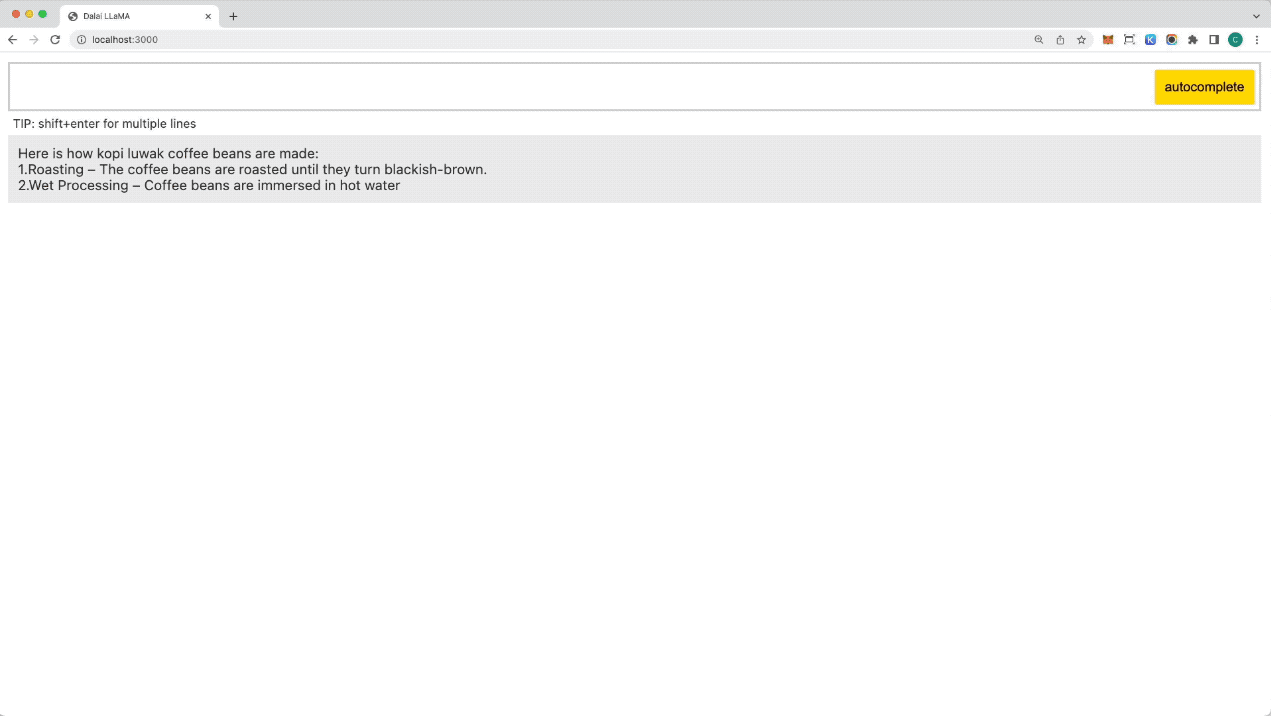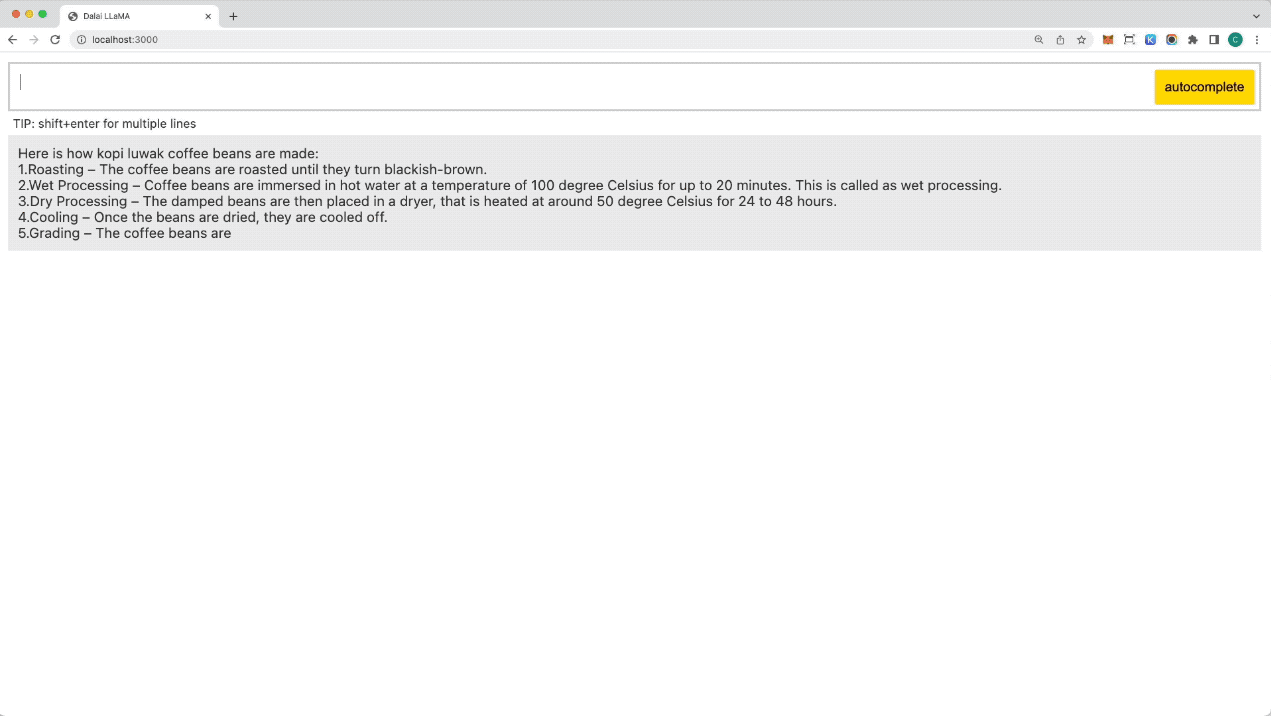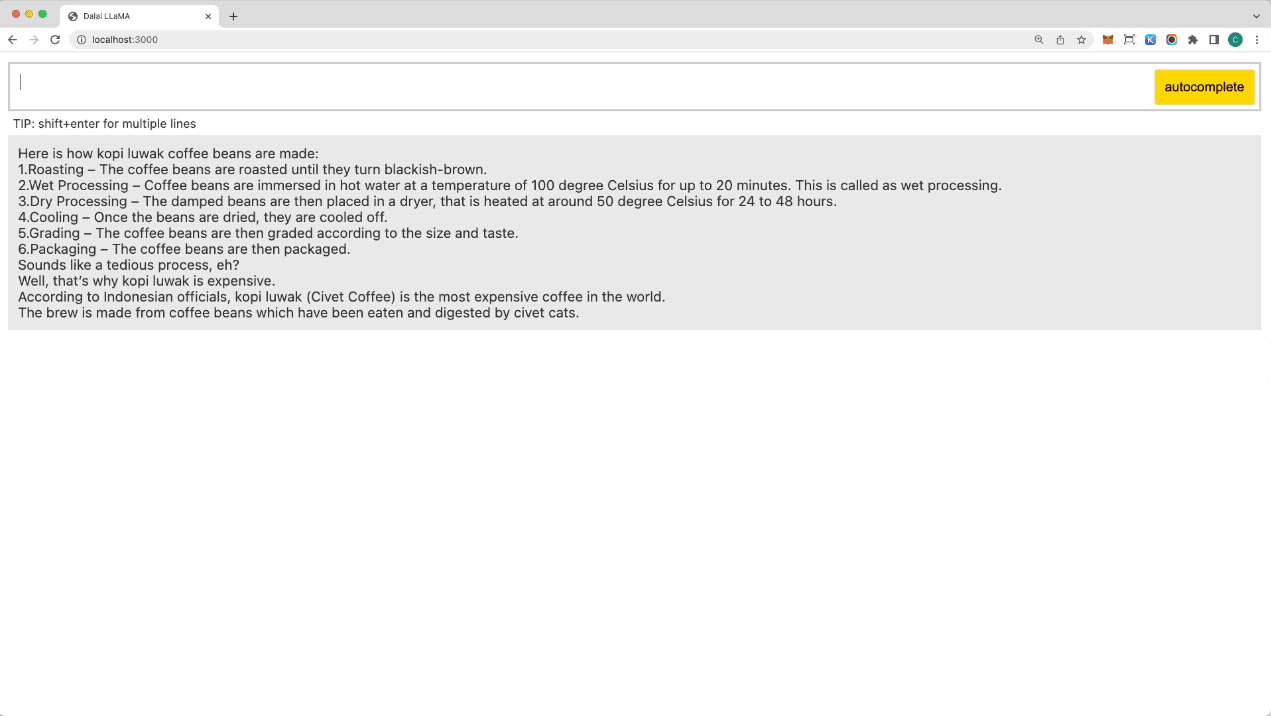
Then go to http://localhost:3000
Above two commands do the following:
- First installs the 7B module (default)
- Then starts a web/API server at port 3000
Install
Basic install (7B model only)
npx dalai llama
Install all models
npx dalai llama 7B 13B 30B 65B
The install command :
- Creates a folder named
dalaiunder your home directory (~) - Installs and builds the llama.cpp project under
~/dalai - Downloads all the requested models from the llama-dl CDN to
~/dalai/models - Runs some tasks to convert the LLaMA models so they can be used
API
Dalai is also an NPM package:
- programmatically install
- locally make requests to the model
- run a dalai server (powered by socket.io)
- programmatically make requests to a remote dalai server (via socket.io)
Dalai is an NPM package. You can install it using:
npm install dalai
1. constructor()
Syntax
const dalai = new Dalai(url)
url: (optional)- if unspecified, it uses the node.js API to directly run dalai
- if specified (for example
ws://localhost:3000) it looks for a socket.io endpoint at the URL and connects to it.
Examples
Initializing a client that connects to a local model (no network):
const dalai = new Dalai()
Initializing a client that connects to a remote dalai server (a dalai server must be running at the URL):
const dalai = new Dalai("ws://localhost:3000")
2. request()
Syntax
dalai.request(req, callback)
req: a request object. made up of the following attributes:prompt: (required) The prompt stringmodel: (required) The model name to query ("7B", "13B", etc.)threads: The number of threads to use (The default is 8 if unspecified)n_predict: The number of tokens to return (The default is 128 if unspecified)seed: The seed. The default is -1 (none)top_ktop_ptemp: temperaturebatch_size: batch size
callback: the streaming callback function that gets called every time the client gets any token response back from the model
Examples
1. Node.js
Using node.js, you just need to initialize a Dalai object with new Dalai() and then use it.
const Dalai = require('dalai')
new Dalai().request({
model: "7B",
prompt: "The following is a conversation between a boy and a girl:",
}, (token) => {
process.stdout.write(token)
})
2. Non node.js (socket.io)
To make use of this in a browser or any other language, you can use thie socket.io API.
Step 1. start a server
First you need to run a Dalai socket server:
// server.js
const Dalai = require('dalai')
new Dalai().serve(3000) // port 3000
Step 2. connect to the server
Then once the server is running, simply make requests to it by passing the ws://localhost:3000 socket url when initializing the Dalai object:
const Dalai = require("dalai")
new Dalai("ws://localhost:3000").request({
model: "7B",
prompt: "The following is a conversation between a boy and a girl:",
}, (token) => {
console.log("token", token)
})
3. serve()
Syntax
Starts a socket.io server at port
dalai.serve(port)
Examples
const Dalai = require("dalai")
new Dalai().serve(3000)
4. http()
Syntax
connect with an existing http instance (The http npm package)
dalai.http(http)
http: The http object
Examples
This is useful when you're trying to plug dalai into an existing node.js web app
const app = require('express')();
const http = require('http').Server(app);
dalai.http(http)
http.listen(3000, () => {
console.log("server started")
})