Merge pull request #26 from LucaDorinAnton/master
Small fixes and changes
This commit is contained in:
commit
51253b2169
36
README.md
36
README.md
|
|
@ -263,7 +263,7 @@ Data uploaded into S3 is spread across multiple files and facilities. The files
|
|||
|
||||
5.) transfer acceleration (an optional speed increase for moving objects via Cloudfront)
|
||||
|
||||
6.) cross region replication (more HA than offered by default
|
||||
6.) cross region replication (more HA than offered by default)
|
||||
|
||||
- Bucket policies secure data at the bucket level while access control lists secure data at the more granular object level.
|
||||
- By default, all newly created buckets are private.
|
||||
|
|
@ -453,7 +453,7 @@ Snowball is a giant physical disk that is used for migrating high quantities of
|
|||
## Storage Gateway
|
||||
|
||||
### Storage Gateway Simplified:
|
||||
Storage Gateway is a service that connects on-premise environments with cloud-based storage in order to seamlessly and securely integrate an on-prem application with a cloud storage backend. and Volume Gateway as a way of storing virtual hard disk drives in the cloud.
|
||||
Storage Gateway is a service that connects on-premise environments with cloud-based storage in order to seamlessly and securely integrate an on-prem application with a cloud storage backend. Storage Gateway comes in three flavors: File Gateway, Volume Gateway and Tape Gateway.
|
||||
|
||||
|
||||
### Storage Gateway Key Details:
|
||||
|
|
@ -548,7 +548,7 @@ The following table highlights the many instance states that a VM can be in at a
|
|||
- If you would like a balance of risk tolerance and network performance, use Partitioned Placement Groups.
|
||||
|
||||
- Each placement group name within your AWS must be unique
|
||||
- You can move an existing instance into a placement group guaranteed that it is in a stopped state. You can move the instance via the CLI or an AWS SDK, but not the console. You can also take a snapshot of the existing instance, convert it into an AMI, and launch it into the placement group where you desire it to be.
|
||||
- You can move an existing instance into a placement group provided that it is in a stopped state. You can move the instance via the CLI or an AWS SDK, but not the console. You can also take a snapshot of the existing instance, convert it into an AMI, and launch it into the placement group where you desire it to be.
|
||||
|
||||
## Elastic Block Store (EBS)
|
||||
|
||||
|
|
@ -881,7 +881,7 @@ Automated backups are enabled by default. The backup data is stored freely up to
|
|||
- Network traffic to and from the database is encrypted using Secure Sockets Layer (SSL).
|
||||
- You can use IAM to centrally manage access to your database resources, instead of managing access individually on each DB instance.
|
||||
- For applications running on Amazon EC2, you can use profile credentials specific to your EC2 instance to access your database instead of a password, for greater security
|
||||
- Encryption at rest is supported for all six flavors of DB for RDS. Encryption is done using the AWS KMS service. Once the RDS instance is encryption enabled, the data in the DB becomes encrypted as well as all backups (automated or snapshots) and read replicas.
|
||||
- Encryption at rest is supported for all six flavors of DB for RDS. Encryption is done using the AWS KMS service. Once the RDS instance has encryption enabled, the data in the DB becomes encrypted as well as all backups (automated or snapshots) and read replicas.
|
||||
- After your data is encrypted, Amazon RDS handles authentication of access and decryption of your data transparently with a minimal impact on performance. You don't need to modify your database client applications to use encryption.
|
||||
- Amazon RDS encryption is currently available for all database engines and storage types. However, you need to ensure that the underlying instance type supports DB encryption.
|
||||
- You can only enable encryption for an Amazon RDS DB instance when you create it, not after the DB instance is created and
|
||||
|
|
@ -900,7 +900,7 @@ Aurora is the AWS flagship DB known to combine the performance and availability
|
|||
### Aurora Key Details:
|
||||
- In case of an infrastructure failure, Aurora performs an automatic failover to a replica of its own.
|
||||
- Amazon Aurora typically involves a cluster of DB instances instead of a single instance. Each connection is handled by a specific DB instance. When you connect to an Aurora cluster, the host name and port that you specify point to an intermediate handler called an endpoint. Aurora uses the endpoint mechanism to abstract these connections. Thus, you don't have to hard code all the host names or write your own logic for load-balancing and rerouting connections when some DB instances aren't available.
|
||||
- By default, there are 2 copies in a minimum of 3 availability zones for 6 copies total for all of your Aurora data. This makes it possible for it to handle the potential loss of up to 2 copies of your data without impacting write availability and up to 3 copies of your data without impacting read availability.
|
||||
- By default, there are 2 copies in a minimum of 3 availability zones for 6 total copies of all of your Aurora data. This makes it possible for it to handle the potential loss of up to 2 copies of your data without impacting write availability and up to 3 copies of your data without impacting read availability.
|
||||
- Aurora storage is self-healing and data blocks and disks are continuously scanned for errors. If any are found, those errors are repaired automatically.
|
||||
- Aurora replication differs from RDS replicas in the sense that it is possible for Aurora's replicas to be both a standby as part of a multi-AZ configuration as well as a target for read traffic. In RDS, the multi-AZ standby cannot be configured to be a read endpoint and only read replicas can serve that function.
|
||||
- With Aurora replication, you can have up to fifteen copies. If you want downstream MySQL or PostgreSQL as you replicated copies, then you can only have 5 or 1.
|
||||
|
|
@ -911,7 +911,7 @@ Aurora is the AWS flagship DB known to combine the performance and availability
|
|||
|
||||
- Automated backups are always enabled on Aurora instances and backups don’t impact DB performance. You can also take snapshots which also don’t impact performance. Your snapshots can be shared across AWS accounts.
|
||||
- A common tactic for migrating RDS DBs into Aurora RDs is to create a read replica of a RDS MariaDB/MySQL DB as an Aurora DB. Then simply promote the Aurora DB into a production instance and delete the old MariaDB/MySQL DB.
|
||||
- Aurora starts w/ 10GB and scales per 10GB all the way to 64 TB via storage autoscaling. Aurora's computing power scales up to 32vCPUs and 244GB memory
|
||||
- Aurora starts w/ 10GB and scales per 10GB all the way to 128 TB via storage autoscaling. Aurora's computing power scales up to 32vCPUs and 244GB memory
|
||||
|
||||
### Aurora Serverless:
|
||||
- Aurora Serverless is a simple, on-demand, autoscaling configuration for the MySQL/PostgreSQl-compatible editions of Aurora. With Aurora Serverless, your instance automatically scales up or down and starts on or off based on your application usage. The use cases for this service are infrequent, intermittent, and unpredictable workloads.
|
||||
|
|
@ -946,7 +946,7 @@ Amazon DynamoDB is a key-value and document database that delivers single-digit
|
|||
- DynamoDB is stored via SSD which is why it is so fast.
|
||||
- It is spread across 3 geographically distinct data centers.
|
||||
- The default consistency model is Eventually Consistent Reads, but there are also Strongly Consistent Reads.
|
||||
- The difference between the two consistency models is the one second rule. With Eventual Consistent Reads, all copies of data are usually reached within one second. A repeated read after a short period of time should return the updated data. However, if you need to read updated data within or less than a second and this needs to be a guarantee, then strongly consistent reads are your best bet.
|
||||
- The difference between the two consistency models is the one second rule. With Eventual Consistent Reads, all copies of data are usually identical within one second after a write operation. A repeated read after a short period of time should return the updated data. However, if you need to read updated data within or less than a second and this needs to be a guarantee, then strongly consistent reads are your best bet.
|
||||
- If you face a scenario that requires the schema, or the structure of your data, to change frequently, then you have to pick a database which provides a non-rigid and flexible way of adding or removing new types of data. This is a classic example of choosing between a relational database and non-relational (NoSQL) database. In this scenario, pick DynamoDB.
|
||||
- A relational database system does not scale well for the following reasons:
|
||||
- It normalizes data and stores it on multiple tables that require multiple queries to write to disk.
|
||||
|
|
@ -1030,7 +1030,7 @@ The ElastiCache service makes it easy to deploy, operate, and scale an in-memory
|
|||
- Amazon ElastiCache offers fully managed Redis and Memcached for the most demanding applications that require sub-millisecond response times.
|
||||
- For data that doesn’t change frequently and is often asked for, it makes a lot of sense to cache said data rather than querying it from the database.
|
||||
- Common configurations that improve DB performance include introducing read replicas of a DB primary and inserting a caching layer into the storage architecture.
|
||||
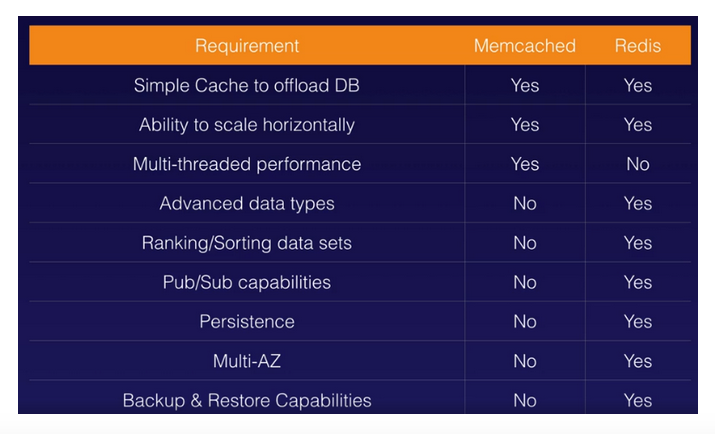
- MemcacheD is for simple caching purposes with horizontal scaling and multi-threaded performance, but if you require more complexity for your caching environment then choose Redis.
|
||||
- Memcached is for simple caching purposes with horizontal scaling and multi-threaded performance, but if you require more complexity for your caching environment then choose Redis.
|
||||
- A further comparison between MemcacheD and Redis for ElastiCache:
|
||||
|
||||
|
||||
|
|
@ -1049,7 +1049,7 @@ Amazon Route 53 is a highly available and scalable Domain Name System (DNS) serv
|
|||
- NS records, or Name Server records, are used by the Top Level Domain hosts (.org, .com, .uk, etc.) to direct traffic to the Content servers. The Content DNS servers contain the authoritative DNS records.
|
||||
- Browsers talk to the Top Level Domains whenever they are queried and encounter domain name that they do not recognize.
|
||||
1. Browsers will ask for the authoritative DNS records associated with the domain.
|
||||
2. Because the Top Level Domain contains NS records, the TLD can in turn queries the Name Servers for their own SOA.
|
||||
2. Because the Top Level Domain contains NS records, the TLD can in turn query the Name Servers for their own SOA.
|
||||
3. Within the SOA, there will be the requested information.
|
||||
4. Once this information is collected, it will then be returned all the way back to the original browser asking for it.
|
||||
- In summary: Browser -> TLD -> NS -> SOA -> DNS record. The pipeline reverses when the correct DNS record is found.
|
||||
|
|
@ -1098,9 +1098,9 @@ When an EC2 instance behind an ELB fails a health check, the ELB stops sending t
|
|||
- Application LBs
|
||||
- Network LBs
|
||||
- Classic LBs.
|
||||
- **Application LBs** are best suited for HTTP(S) traffic and they balance load on layer 7. They are intelligent enough to be application aware and Application Load Balancers also support path-based routing, host-based routing and support for containerized applications. As an example, if you change your web browser’s language into French, an Application LB has visibility of the metadata it receives from your browser which contains details about the language you use. To optimize your browsing experience, it will then route you to the French-language servers on the backend behind the LB. You can also create advanced request routing, moving traffic into specific servers based on rules that you set yourself for specific cases.
|
||||
- **Application LBs** are best suited for HTTP(S) traffic and they balance load on layer 7 OSI. They are intelligent enough to be application aware and Application Load Balancers also support path-based routing, host-based routing and support for containerized applications. As an example, if you change your web browser’s language into French, an Application LB has visibility of the metadata it receives from your browser which contains details about the language you use. To optimize your browsing experience, it will then route you to the French-language servers on the backend behind the LB. You can also create advanced request routing, moving traffic into specific servers based on rules that you set yourself for specific cases.
|
||||
- **Network LBs** are best suited for TCP traffic where performance is required and they balance load on layer 4. They are capable of managing millions of requests per second while maintaining extremely low latency.
|
||||
- **Classic LBs** are the legacy ELB produce and they balance either on HTTP(S) or TCP, but not both. Even though they are the oldest LBs, they still support features like sticky sessions and X-Forwarded-For headers.
|
||||
- **Classic LBs** are the legacy ELB product and they balance either on HTTP(S) or TCP, but not both. Even though they are the oldest LBs, they still support features like sticky sessions and X-Forwarded-For headers.
|
||||
- If you need flexible application management and TLS termination then you should use the Application Load Balancer. If extreme performance and a static IP is needed for your application then you should use the Network Load Balancer. If your application is built within the EC2 Classic network then you should use the Classic Load Balancer.
|
||||
- The lifecycle of a request to view a website behind an ELB:
|
||||
1. The browser requests the IP address for the load balancer from DNS.
|
||||
|
|
@ -1154,7 +1154,7 @@ AWS Auto Scaling lets you build scaling plans that automate how groups of differ
|
|||
- When it comes to actually scale your instance groups, the Auto Scaling service is flexible and can be done in various ways:
|
||||
- Auto Scaling can scale based on the demand placed on your instances. This option automates the scaling process by specifying certain thresholds that, when reached, will trigger the scaling. This is the most popular implementation of Auto Scaling.
|
||||
- Auto Scaling can ensure the current number of instances at all times. This option will always maintain the number of servers you want running even when they fail.
|
||||
- Auto Scaling can scale only with manual intervention. If want to control all of the scaling yourself, this option makes sense.
|
||||
- Auto Scaling can scale only with manual intervention. If you want to control all of the scaling yourself, this option makes sense.
|
||||
- Auto Scaling can scale based on a schedule. If you can reliably predict spikes in traffic, this option makes sense.
|
||||
- Auto Scaling based off of predictive scaling. This option lets AWS AI/ML learn more about your environment in order to predict the best time to scale for both performance improvements and cost-savings.
|
||||
- In maintaining the current running instance, Auto Scaling will perform occasional health checks on the running instances to ensure that they are all healthy. When the service detects that an instance is unhealthy, it will terminate that instance and then bring up a new one online.
|
||||
|
|
@ -1207,10 +1207,10 @@ VPC lets you provision a logically isolated section of the AWS cloud where you c
|
|||
- When you create a VPC, you must assign it an IPv4 CIDR block. This CIDR block is a range of private IPv4 addresses that will be inherited by your instances when you create them.
|
||||
- The IP range of a default VPC is always **/16**.
|
||||
- When creating IP ranges for your subnets, the **/16** CIDR block is the largest range of IPs that can be used. This is because subnets must have just as many IPs or fewer IPs than the VPC it belongs to. A **/28** CIDR block is the smallest IP range available for subnets.
|
||||
- With CIDR in general, a **/32** denotes a single IP address and **/0** refers to the entire network The higher you go in CIDR, the more narrow the IP range will be.
|
||||
- With CIDR in general, a **/32** denotes a single IP address and **/0** refers to the entire network. The higher you go in CIDR, the more narrow the IP range will be.
|
||||
- The above information about IPs is in regards to both public and private IP addresses.
|
||||
- Private IP addresses are not reachable over the Internet and instead are used for communication between the instances in your VPC. When you launch an instance into a VPC, a private IP address from the IPv4 address range of the subnet is assigned to the default network interface (eth0) of the instance.
|
||||
- This means that all instances within a VPC has a private IP, but only those selected to communicate with the external world have a public IP.
|
||||
- This means that all instances within a VPC have a private IP, but only those selected to communicate with the external world have a public IP.
|
||||
- When you launch an instance into a subnet that has public access via an Internet Gateway, both a public IP address and a private IP address are created. The public IP address is instead assigned to the primary network interface (eth0) that's created for the instance. Externally, the public IP address is mapped to the private IP address through network address translation (NAT).
|
||||
- You can optionally associate an IPv6 CIDR block with your VPC and subnets, and assign IPv6 addresses from that block to the resources in your VPC.
|
||||
- VPCs are region specific and you can have up to five VPCs per region.
|
||||
|
|
@ -1255,7 +1255,7 @@ VPC lets you provision a logically isolated section of the AWS cloud where you c
|
|||
|
||||
|
||||
### NAT Instances vs. NAT Gateways:
|
||||
- Attaching an Internet Gateway to a VPC allows instances with public IPs to directly access the internet. NAT does a similar thing, however it is for instances that do not have a public IP. It serves as an intermediate step which allow private instances to first masked their own private IP as the NAT's public IP before accessing the internet.
|
||||
- Attaching an Internet Gateway to a VPC allows instances with public IPs to directly access the internet. NAT does a similar thing, however it is for instances that do not have a public IP. It serves as an intermediate step which allow private instances to first mask their own private IP as the NAT's public IP before accessing the internet.
|
||||
- You would want your private instances to access the internet so that they can have normal software updates. NAT prevents any initiating of a connection from the internet.
|
||||
- **NAT instances** are individual EC2 instances that perform the function of providing private subnets a means to securely access the internet.
|
||||
- Because they are individual instances, High Availability is not a built-in feature and they can become a choke point in your VPC. They are not fault-tolerant and serve as a single point of failure. While it is possible to use auto-scaling groups, scripts to automate failover, etc. to prevent bottlenecking, it is far better to use the NAT Gateway as an alternative for a scalable solution.
|
||||
|
|
@ -1397,7 +1397,7 @@ VPC lets you provision a logically isolated section of the AWS cloud where you c
|
|||
## Simple Queuing Service (SQS)
|
||||
|
||||
### SQS Simplified:
|
||||
SQS is a web-based service that gives you access to a message queue that can be used to store messages while waiting for a queue to process them. It helps in the decoupling of systems and the horizontal scaling of AWS resources.
|
||||
SQS is a web-based service that gives you access to a message queue that can be used to store messages while waiting for another service to process them. It helps in the decoupling of systems and the horizontal scaling of AWS resources.
|
||||
|
||||
### SQS Key Details:
|
||||
- The point behind SQS is to decouple work across systems. This way, downstream services in a system can perform work when they are ready to rather than when upstream services feed them data.
|
||||
|
|
@ -1461,7 +1461,7 @@ Amazon Kinesis makes it easy to collect, process, and analyze real-time, streami
|
|||
- It is a fully managed service that automatically scales to match the throughput of your data and requires no ongoing administration. It can also batch, compress, and encrypt the data before loading it, minimizing the amount of storage used at the destination and increasing security.
|
||||
- There are three different types of Kinesis:
|
||||
- Kinesis Streams
|
||||
- Kinesis Streams works where the data producers stream their data into Kinesis Streams which can retain the data that enters it from one day up until 7 days. Once inside
|
||||
- Kinesis Streams works where the data producers stream their data into Kinesis Streams which can retain the data from one day up until 7 days. Once inside
|
||||
Kinesis Streams, the data is contained within shards.
|
||||
- Kinesis Streams can continuously capture and store terabytes of data per hour from hundreds of thousands of sources such as website clickstreams, financial
|
||||
transactions, social media feeds, IT logs, and location-tracking events. For example: purchase requests from a large online store like Amazon, stock prices, Netflix
|
||||
|
|
@ -1619,7 +1619,7 @@ The following section includes services, features, and techniques that may appea
|
|||
### What is the Amazon Cognito?
|
||||
- Before discussing Amazon Cognito, it is first important to understand what Web Identity Federation is. Web Identity Federation lets you give your users access to AWS resources after they have successfully authenticated into a web-based identity provider such as Facebook, Google, Amazon, etc. Following a successful login into these services, the user is provided an auth code from the identity provider which can be used to gain temporary AWS credentials.
|
||||
- Amazon Cognito is the Amazon service that provides Web Identity Federation. You don’t need to write the code that tells users to sign in for Facebook or sign in for Google on your application. Cognito does that already for you out of the box.
|
||||
- Once authenticated into an identity provider (say with Facebook as an example), the provider supplies an auth token. This auth token is then supplied to cognito which responds with limited access to your AWS environment. You dictate how limited you would like this access to be in the IAM role.
|
||||
- Once authenticated into an identity provider (say with Facebook as an example), the provider supplies an auth token. This auth token is then supplied to Cognito which responds with limited access to your AWS environment. You dictate how limited you would like this access to be in the IAM role.
|
||||
- Cognito's job is broker between your app and legitimate authenticators.
|
||||
- *Cognito User Pools* are user directories that are used for sign-up and sign-in functionality on your application. Successful authentication generates a JSON web token. Remember user pools to be user based. It handles registration, recovery, and authentication.
|
||||
- *Cognito Identity Pools* are used to allow users temp access to direct AWS Services like S3 or DynamoDB. Identity pools actually go in and grant you the IAM role.
|
||||
|
|
|
|||
Loading…
Reference in New Issue